

This page provides some instructions on the use of the Open OnDemand Portal (OOD) for interacting with the UMD HPC clusters. This is a good place to start reading for new users to the cluster, especially those who are not very familiar with using the Linux/Unix command line, as it has features that can increase the usability of the cluster in such cases. However, even advanced users might find various features, in particular Interactive Applications, Batch Jobs and Shell Access useful, especially when on the road.
NOTE: the OnDemand Portal only provides access to the Deepthought2 and Juggernaut clusters at this time. Access to Bluecrab is NOT supported.
|
|
If you ever use the OnDemand portal from a public/shared system, ALWAYS BE SURE
to COMPLETELY EXIT THE BROWSER when you are finished. Otherwise your login
credentials could be stored in session cookies and the next person to use
the machine might be able to access your accounts on the HPC clusters.
|
Connecting to the OnDemand Portal is easy. Just open a web browser on your desktop/workstation/etc, and go to the URL for the HPC cluster you are using:
| HPC Cluster | URL for OnDemand Portal |
|---|---|
| Zaratan | https://portal.zaratan.umd.edu |
| Juggernaut | https://portal.juggernaut.umd.edu |
| MARCC/Bluecrab | No OnDemand Portal at this time |
|
|
You must completely exit your web browser in order to fully log out
from the OnDemand portal. If you ever use OnDemand from a public/shared
system, ALWAYS BE SURE
to COMPLETELY EXIT THE BROWSER when you are finished. Otherwise your login
credentials could be stored in session cookies and the next person to use
the machine might be able to access your accounts on the HPC clusters.
|
You will be prompted for your username and password, use the same credentials
you use to access the login node for the cluster. Once logged in, you will
see the Dashboard home page, the main feature of which is the red navigation
menu bar across the top, as shown below:

The navigation menu bar is what you will use to access much of the portal functionality. A similar navigation bar occurs on most of the other pages, although a different color and fewer and different menu options. Note the following features of the dashboard navigation bar, going from left to right:
A) is a label with the name of the cluster
the OnDemand portal is for. Although not particularly needed on the dashboard
screen (since the cluster is clearly indicated in the large logo beneath the
navigation bar), this occurs on most of the child screens for portal, where it
might be more useful, and you can click on it to get back to the dashboard.
Files dropdown menu (labeled B in
the screenshot). The dropdown will give a list of directories, including
your home and lustre directories, and selecting one of the will open the
OnDemand File Manager in that directory.
Jobs menu (indicated by the C),
which provides access
to utilities for dealing with batch jobs. In particular,
there is a link to monitoring your batch jobs and
a link to the Clusters dropdown menu (labeled D) comes
next. Currently we have separate portals for each cluster, so this will only
have a single item, which provides shell access to one
of the login nodes for the specified cluster. You will need to use the Linux/Unix
command line to make use of that, but it is handy if you need to access the
cluster from a machine without an ssh client installed.
Interactive Apps drop down menu (marked E) returns
a list of interactive applications supported by
the portal. These will launch interactive jobs running the specified application
and supporting a graphical interface through the web client. The jobs go through
the scheduler and run on compute nodes, so there might be significant waits before
resources are available if the cluster is busy. But it does allow graphical displays
without needing to install X on your workstation. The My Interactive Sessions
entry (indicated by the F) will allow you to review, connect to disconnected
sessions, and/or terminate interactive sessions.
Develop menu (G in the screenshot).
This is for more advanced
users who are working with DIT to develop job templates, etc. to assist less advanced
users in their field. This is discussed more in the section on
Developer documentation
Contact systems
staff if you are interested in developing job templates.
Help drop down menu (marked H) contains links
to URLs to submit help tickets, access the HPC documentation, change your
password, etc.
I in the screenshot)
list the username with which you are logged into the system. That could be helpful
for people with a normal account and say a temporary class account. There is also
a Log Out button; do NOT use this. In order to provide
it's functionality, OnDemand uses cookies, cached passwords, etc., and you need
to fully exit your web browser to really log out. The Log Out button
will not really log you out.
Note: to fully log out, you should exit the web browser, as otherwise some credentials might still be cached, enabling the browser to login automatically (without your entering a password) if the site is revisited within a day or so. ALWAYS FULLY EXIT the web browser, especially on shared machines. You might also want to consider using private browsing sessions if your web browser supports it.
|
|
If you ever use the OnDemand portal from a public/shared system, ALWAYS BE SURE
to COMPLETELY EXIT THE BROWSER when you are finished. Otherwise your login
credentials could be stored in session cookies and the next person to use
the machine might be able to access your accounts on the HPC clusters.
|
The first bit of functionality we will discuss is the OOD File Manager
app, which is accessed via the leftmost Files drop down menu on the navigation menu bar
at the top of the Dashboard. When clicked, you get a choice of where you
want the File Manager to start (where USERNAME is your username
below):
NOTE: you will only see the options currently available to you, so you might see only one of the two lustre options.
Click on the directory you wish to explore, and click on it, and the explorer window will open, based in the selected directory.
The File Manager page has a lot going on in it, and here we provide a brief overview to the various components it presents.
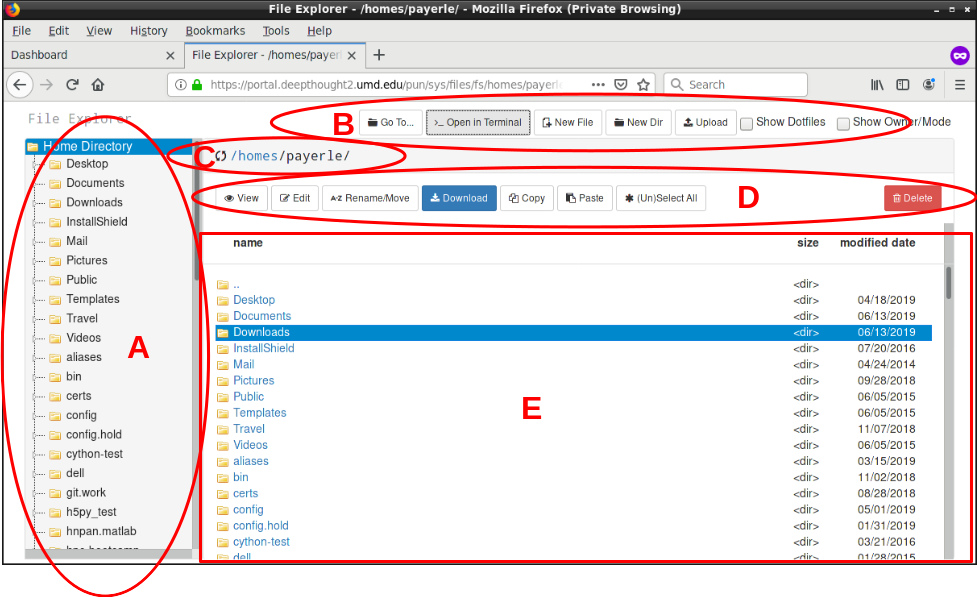
This section gives a brief tutorial on how to navigate to the desired directory in the OOD File Manager. In general, there are several ways to accomplish this.
Probably the easiest way to navigate to directories under the base
directory with which the File Manager was launched is to double click on
the directory name in the file list frame (E).
This will cause the current
directory to descend to the selected directory. To move up the directory
tree, you can double click on the special .. directory at the
type of the directory list (in Unix, .. stands for the parent
directory).
Alternatively, you can double click on a directory in the directory tree view (A). With the ability to expand and collapse branches, this offers an easy way to jump between directories.
Finally, you can also click on the Go To... button in the
main menu bar (B). This will open a
dialog in which you can enter the path to the directory you wish to navigate to.
Whichever choice you use, when you change directories the path listed
in the current directory field (C)
will be updated to reflect the new path,
and the contents of the file list frame (E)
will show the new directory. Also, the directory tree view (A)
will highlight the appropriate directory,
in most cases. If the directory is not visible in the tree view because the
branch it is in has been collapsed, the closest parent of the branch that is
visible will be highlighted. And if you leave the root branch with which
the File Manager opened (either by using the Go To ... button
or navigating to the parent of the root directory, the Directory Tree view
will just highlight the root directory).
This section gives a quick overview of how to use File Manager to manipulate files. In general, the first step is to navigate to the directory containing the file you wish to manipulate in the main file list frame (E), and select the file you wish to manipulate. (For creating a new file/directory, or uploading a file, just navigate to and open the directory in which the new file/directory should go.)
To see the contents of a file, just select the file and click on the
View button in the file manipulation menu bar (D).
NOTE: the viewer in the File Manager is limited in terms
of what type of files it can view. Text files are OK, and it handles most
common graphical image files (html, pdf, png, jpg, etc).
Using it on other binary files (including ps, zip, tar, various Office
formats, etc) is likely to produce unsatisfactory results. The exact list of
what formats work and which do not is likely dependent on your browser and its
addons/settings.
To create a new empty file or directory, navigate to and open the desired
parent directory, and then click on New File or
New Dir in the main menu bar (B)
for a new file or directory,
respectively. This will open a dialog allowing you to enter the name for the
new file or directory.
To upload a file from your workstation to the cluster, navigate to and
open the desired parent directory, then click the Upload button
in the main menu bar (B).
This will open a dialog with a Browse
button, click on the browse button and a file dialog will open. Select the
file on your workstation which you wish to upload, and it will be uploaded
to the currently open directory.
To download a file from the cluster to your workstation, navigate to the
directory containing the file and select the file. Then download the file
as you would any other web content (e.g. on Firefox, right click on the file
and select Save Link as).
To edit the file, you can simple navigate to the containing directory,
select the file, and then click on the Edit button in the
file manipulation menu bar (D). This will open a simple
WYSIWYG editor
inside OOD. Make your eidts, and when you are done, click on the blue
Save button in the upper left. To abandon your edits, simply
abandon the page without saving (i.e. close the browser window).
To delete a file or directory, navigate to the parent directory and select
the file/directory you wish to delete. Then click on the red
Delete button on the right of the file manipulation menu
bar (D).
This will open a dialog confirming that you wish to delete the object.
NOTE: Once you delete something, it is GONE,
it cannot be recovered. NOTE: The Delete button will allow
you to delete a directory with files and/or subdirectories without any
additional warnings (other than the aforementioned basic confirmation).
USE THE DELETE BUTTON WITH CARE.
The Rename/Move allows you to rename or move a file. Just
navigate to the parent directory and select the file to be renamed/moved, and
then click the Rename/Move button. This will open a dialog
allowing you to type the new file name (defaulting to the current name). You
can then type a new name. If you do not include a directory path separator
("/"), it will rename the file in the same directory. If you include a path
separator, it will move (and possibly rename as well if you changed the base
name) to the new directory. Note: the new directory must
already exist.
To copy one or more files to a new directory, it is
you can use the copy and paste method. Navigate to the
containing directory and select the file(s) you wish to copy (to select
multiple files, first select one, then hold the control key down when selecting
subsequent files. Or you can hold the shift key to select a range of files),
and then click on the Copy button in the file manipulation
menu bar (D). Then navigate to the new directory, and
click the Paste button to copy the files to the new location.
To make a copy of a file in the same directory with a different name is not well supported. I think the best option is to copy and paste the file to a different directory (creating a temp subdirectory if needed), then rename the file in that directory and then move back to the original directory.
Normally, the main file list frame (E)
only shows file/directory name,
size, and modification date. If you click the check box Show Owner/Mode
in the main menu bar (B),
it will also show the file/directory owner
and the mode/permission bits (the latter will be in the standard Unix format).
Also, by default, files and directories whose name start with a '.' (period)
character are omitted in the list --- this is in accord with the standard Unix
custom to treat files with such names as hidden files/directories. You can
check the Show Dotfiles checkbox in the main menu bar
(B) if
you wish to see these "hidden" files.
The Open in Terminal button in the main menu bar
(B)
will open an ssh session on one of the login nodes for the cluster. Despite
being in the File Manager section, it does not automatically change directory
for you. This can be an alternative to installing an ssh client on a system.
One of the more interesting features of the OnDemand portal is that availability of "interactive applications". These allow you to launch an interactive session on one of the cluster compute nodes. What is especially nice is that these applications support graphics without the overhead of installing an X server on your workstation --- you get a full graphical interactive session over your web browser.
You can access the various interactive apps from the Interactive
Apps drop down on the main, top menu bar from the OnDemand
dashboard. They are also listed in the navigation frame on the left from the
interactive app menu page, allowing you to quickly jump around between
applications.
When an interactive app is launched, it waits in the queue for an available
node just like any other job. Depending on how busy the cluster is, the
wait time can be a couple of minutes to several hours. You can often reduce
the wait time by using the debug partition, but in those cases
your interactive job is limited to 15 minutes. Even in the non-debug
partitions, various choices you make (such as number of cores/nodes, walltime,
if you need GPUs or not) can affect your wait times.
|
|
The VNC connection used for displaying the GUI is rather dependent on the
browser being used. In particular, we have seen issues when connecting with
Chrome browsers on Windows workstations. We recommend Firefox for Windows
users.
|
The Division of IT is working to add more applications to the list of those supported in this section of the portal, so it might be worth checking back here periodically. Currently, the following interactive applications are supported:
When you click on an interactive app in the drop-down list, you end up
on the main setup page for that application. This starts with a line or
two describing the application, and then has a form with a number of fields
to fill out. At the bottom of the form is a blue Launch button;
clicking this button will cause the interactive job to be submitted.
Although the form fields are application specific, a number of the fields crop up frequently and will be discussed here.
default and debug. The debug
partition is very high priority, so your job will likely spend less time
waiting in the queue, but is limited to 15 minutes of runtime for your
interactive job. It is useful for quick testing or checking something, but
you will typically want to use the default setting, which
will send your job to either the high-priority or
standard partition
depending on the allocation account being charged against.. For more
information regarding partitions
.
NOTE: There are currently no GPU enabled nodes in the
debug partition, so you must use default if you
need a GPU-enabled node.
debug partition, make sure you request no more than 15 minutes.
Note: At this time, you must enter an integer number of
minutes. I.e., values like 1-12:00:00 for one day and twelve hours are
NOT currently accepted here.
At the bottom is a blue Launch button, when all the form
elements are set to the proper values you can click on that button to submit
the interactive job. At this point you will be redirectored to an interactive
session page, which show information about the job as seen below:

There is a heading bar at the top, with background colors representing
various states of the job. On the left side of this bar are the name of
the application (labeled A in the diagram, and showing
Deepthought2
since this screenshot for the Deepthought2 desktop application) and the
job number (labeled B or 3134478
in this example).
On the right side of this menu bar are information about the size of the
job (labeled C; this example requested 1 core on 1 node)
and the
state of the job (labeleed D, with a value of
Running in this screenshot).
The background color of the bar varies with job state (gray for pending,
blue for starting, green for running). The session data will go away when the
job completes.
When the job is running, there will be a field (labeled E in the diagram) showing on which node the job is running, this field is absent until the job starts. The session ID, the long string of letters and numbers ( labeled H in our screenshot), is how the portal identifies your job. That string represents a directory under the ondemand subfolder in your home directory where the portal saves various information related to your job. You can click on the link to open the directory in the File Manager (and see the full path, if desired). By default, the output and any error files will go hear, as well as copies of the actual batch script used, etc.
If you change your mind about the job, you can use the red
Delete button (strong>F on the right just below the
header bar to cancel/delete the job. If clicked on, a dialog will open asking
you to confirm the action.
The blue button at the lower left (indicated by the I in the diagram)
is probably the piece you are most interested in. It typically will be labeled
with the a word like "Launch" or "Connect", e.g. Launch Deepthought2,
Launch MATLAB,
or Connect to Jupyter. If you click this button,
your browser will open a new tab containing an interactive graphical session
on the node your job is running. E.g., for the interactive Desktop application,
you get an Unix X11 desktop; for the Matlab application, you get the GUI for
the Matlab program; for Jupyter you get an interface to Jupyter.
You can interact with the program basically just as you
would if you were sitting at a workstation.
While all of the applications discussed in this section are referred to as "Interactive applications", and indeed are interactive in that they enable you to interact directly with the application, many also support a "detached" mode. I.e., it is possible to launch an interactive Matlab session, do some work, then start a calculation that will take a couple of hours, and disconnect from the session (and even possibly log out and/or shutdown your workstation/laptop). Assuming you allocated enough time to the interactive session, you could then reconnect later to check up on the progress of the calculation.
Note: When you
are finished with an interactive session, you should use the Delete
button in the My Interactive Sessions tab to terminate the interactive session.
You can also use that tab to ensure that the interactive application is truly terminated
and not just disconnected (when terminated, it will not appear as an active session in
that page).
Note: your allocation will be charged for the entire duration of the interactive session, whether you are connected to the session or not.
While disconnecting from interactive sessions, like described above, is permissible, please be mindful of the fact that the HPC resources are valuable, and it is wasteful and inconsiderate to colleagues to leave an active session sitting idly. So, returning to our Matlab example, if you start a calculation in an interactive session that you expect will take about two hours to complete, it is reasonable to disconnect and reconnect an hour or two later. But if you disconnect and only reconnect four hours later, the Matlab process would likely have been sitting idle for about two hours, despite the resources it is running on being reserved for your use --- that would be wasteful and inconsiderate. Generally, it is best to use the Interactive Applications feature when you really will be interacting with the application, and submit batch jobs for longer calculations which do not require user interaction.
Most (but not all) of the interactive applications make use of the
noVNC javascript implementation of
the VNC protocol
for handling the remote display. In these cases, there will be
a noVNC menu bar on the left edge of the screen. It is normally minimized,
looking only like a small tab with an arrow pointing to the right. Click on
that to open the menu (you can click on the arrow again to minimize it). In
particular, the bottom most icon (sort of a rectangle split at a 45 degree
angle with a line through it) is the button for disconnecting the session.
Clicking on that will disconnect you from the session, but still leave
the job running. You can use the My Interactive Sessions on the
main OnDemand top menu bar to reconnect to the session later.
Note: Disconnecting from the session does NOT
end the job --- use the Delete button (F) to
terminate the job. Your allocation account will be charged until the job is
terminated.
The View Only (Share-able Link) button (labeled
J)
behaves somewhat similarly, but only allows one to view the program. You are
unable to use the mouse or keyboard to control the program or enter data.
The intent is that you can email the URL for this link to a colleague, and then
they can watch as you interact with the program, presumably so one of you can
assist the other with the use of the program.
If you disconnect from an interactive job but leave it running, you can
use the My Interactive Sessions item on the main top menubar
for the OnDemand dashboard to see what active interactive sessions you
have. This will list the sessions and provide a blue button to reconnect to
the session. You can also use this to confirm that all interactive sessions
have been completely terminated and not just disconnect ---
Note: disconnected but not terminated interactive sessions
are still charging your allocation account. Use the Delete button
(labeled F in the previous figure)
in the My Interactive Sessions screen to terminate the job when
you are finished.
This application will open an interactive GUI desktop on one of the compute
nodes. When you select the blue button (I in diagram above,
labeled something like Launch noVNS in New Tab or Launch Deepthought2
or Launch Juggernaut) you will get a fairly standard Unix
graphical desktop. You can open applications from the Applications menu (typically in upper
left unless you moved it), etc. just as if you were sitting at a workstation.
This application will start the requested version of Matlab on one of the
compute nodes. When you select the Launch noVNS in New Tab button
(I in diagram above), you will get a fairly standard Unix
desktop running the Matlab GUI. You can enter matlab commands, plot data, etc.
The menu for configuring the job will have a MATLAB version
field allowing you to specify the version of Matlab you wish to run.
This interactive application will allow you to start a jupyter notebook
server on one of the compute nodes. Once the job starts, there should
be a blue Connect to Jupyter button. If you click on that,
you will get a interactive Jupyter session in a new tab.
This tab will show on the Files panel your home directory
from where you can navigate to existing notebooks (file extension:
.ipynb) or you can choose from the New
pulldown menue (top right) whether to create a notebook for
Python3 or R code.
The Logout button in the upper right
of the Jupyter session deserve some special attention.
If you click the Logout button, it will disconnect your
session with the Jupyter server, but the Jupyter server will
continue to run. You can reconnect with the session later from the
My Interactive Sessions menu in the main top menu bar of the
OnDemand dashboard. Note: Your allocation account
will be charged as long as the job is running. So make sure you use the
Delete
Quit if you wish to finish the job. You can verify if you still
have any interactive sessions running from the My Interactive
Sessions option on the main top menu bar in the OnDemand dashboard.
The support for Interactive Applications in OnDemand is nice, but most production work on HPC clusters is done via batch jobs. Typically, one sets up a calculation that will run for many hours, or even days, and submits it to the cluster to run when resources become available (which in itself might take hours), and then return to look at the results after the job is done. Indeed, researchers often submit many jobs that are very similar, differing maybe only in the input data, or due to a slight tweak in a parameter or adjustment to the code.
Traditionally, the setting up and submission of jobs in that sort of production use of the HPC is done from the Unix command line, and while the various Unix command line utilities still probably make that the most efficient route for experienced Unix users, this presents a steep learning curve to potential HPC users without much Unix/Linux experience.
The Job Composer applet in the OnDemand portal can simplify this somewhat. While it does not eliminate all of the complexity involved in submitting batch jobs to the cluster, it does simplify many of the aspects, especially when combined with job templates, whereby you can start with some standard "template" jobs (developed by system administrators and/or other users) and submit these after making the requisite modifications.
The OnDemand portal also provides an easy to use interface for monitoring and managing your batch jobs once they have been submitted.
The Job Composer applet simplifies the process of creating and
submitting batch jobs to the cluster. It is accessible using the
Job Composer
item on the Jobs drop down on the navigation menu
of the OnDemand dashboard (marked C on the
screenshot of the dashboard).
You should see a web page similar to the one shown below. Your
first time visiting the page, you will likely see some popup "help"
windows leading you through the steps needed to create a job;
you can click the Next button in each popup to move on.
If you wish to see that sequence again, you can just click on
the Help button in the navigation bar (D
in the screenshot below).
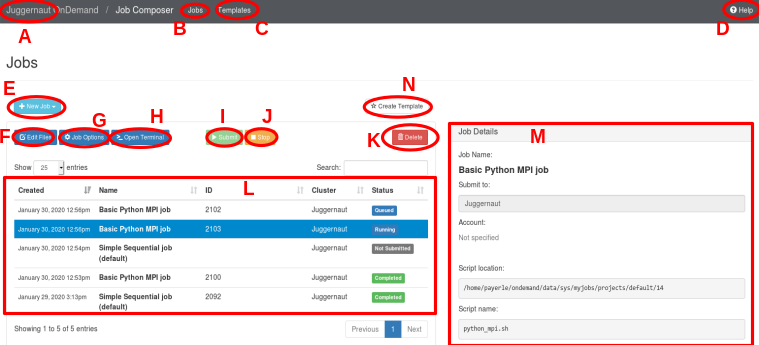
At the top of the screen is the Job Composer navigation bar.
To the left (marked A) is the name of the cluster the
portal is for, and clicking on it will return you to the OnDemand
Dashboard. There are also buttons Jobs (labeled B)
and Templates(labeled C) which indicates which
section of the Job Composer you are in. We are currently in the "Jobs"
section; the "Templates" portion will be discussed more in the
next section. The final piece of the navigation
menu is the Help button at the far right (marked D).
Clicking on this will open a sequence of helpful popups leading you through
the process of creating and submitting a job (I believe this sequence will
also run whenever you start the Job Composer without any jobs listed in
the section marked L).
The Job Composer allows one to create, edit, submit, and manage jobs
based on templates or previously submitted jobs. The composer overloads the
meaning of the term job; when you create a "job" in the Job Composer, it creates
a new directory under the ondemand folder in your home directory and
copies the relevant files to that directory. You then have a chance to edit, add,
and/or delete files in that directory (typically via the OnDemand
file manager), and when you are satisfied, you can submit the job to the
scheduler on the cluster, at which point it becomes a "job" in the traditional HPC
sense (i.e. from the scheduler's perspective). The Job Composer allows you to
easily watch the status of the job, and even cancel the job if desired. You can
also examine the output files generated by the job, and if desired use the Job Composer
to create new jobs based on that job.
The starting point for all of this is the New Job button, labeled
E in the screenshot. When you click on that button, you get four options
for creating a new job:
From Default Template: this will create a job from the default template.
The default template is typcially a fairly basic and generic sequential job, so this
is probably not a great choice in production. But it is useful for learning to use the composer.From Template: This will switch you to the
"Templates" section of the Job Composer and gives you
a selection of templates to choose from. This will be discussed more in
the next section.From Specified Path: this will allow you to create a Job Composer job
from a job created outside of the Job Composer. You will need to specify the path
to the directory containing the job, and some other parameters. The contents of the
directory you specify will be copied into the newly created Job Composer job directory.
From Selected Job: this will copy an existing Job Composer job to
a new Job Composer job. Before you can use this, you must have jobs in your job list
(the table marked L in the screenshot) and have selected one of those jobs.
In production, you most likely will mainly be using the From Template and
From Selected Job options, but for now select the From Default Template
When you do this, a Job Composer job will be created and appear in the job listing (the section
labeled L in the screenshot). The new job will look much like the third job in
the screenshot (the Simple Sequential Job (default) from January 30, 2020 12:54 pm.
Because you just created it, it will be "selected"; this is indicated by the blue highlighting
(like the job with ID 2103 in the screenshot). A couple items to note:
Jobs title, there will be
a message with a light green background saying the job was created.Status of Not Submitted; i.e. it is a Job Composer job, but
it is not yet a Slurm job. Note also that the ID field is empty --- this field
will normally contain the Slurm job ID for the job, but as no Slurm job is associated with
this Job Composer job, it is blank.F,G,H,I,K in
the screenshot) will become active.Job Details section (marked M in the screenshot), which was missing before,
now appears and contains information on the selected (and at this point, only) job. We will discuss
this more below.
The Job Details section (M in the screenshot) contains various
details about the selected Job Composer job. They are fairly self-explanatory, but we point out
several important ones below:
Script location
directory above. This is the equivalent to the script you would pass to the sbatch command
if running from the command line. When the job starts to run, this script is run on the first compute node
assigned to the job and kicks off the calculations, etc.
submit.sh).
Script location directory.
This allows you easy access to the Job directory if you want to verify or make changes using the Unix
shell/command line. Note that this does the same thing as the button Open Terminal labeled
H in the screenshot.
Edit Files button (labeled F in
the screenshot).
The job defined by the default job template is quite simple. The submit script
specifies some information to the scheduler (via the #SBATCH lines), telling it that
it wants 1 CPU core and 1 GB (1024 MB) of RAM for at most 5 minutes on the debug partition,
and that other jobs can run on the same node. It then does a module load to set up
the environment for our hello-umd program, creates a temporary directory in the
local node scratch space, and then outputs some basic information about the job.
It then runs the hello-umd, saving the output to hello.out in the temporary directory,
and then copies the hello.out back to the job submission directory. The hello-umd
is just a simple Hello, World!
program, i.e. it just prints out some identification and a welcome message. (The hello-umd
code has both sequential and MPI variants, so it normally identified which of potentially numerous
processes the greeting comes from. This "default" job just runs the sequential variant, so it should
always be "process 0 of 1", but other job templates use the MPI variant which will print a greeting
from each MPI task.)
Although this job, and indeed most of the job templates, are very simple examples, we tried to write the templates so as to follow good practices even when such are a bit of overkill for such simple cases. We have tried to generously comment the scripts to make it easier to follow what they are doing. We note the following features and practices in this job script and those of most of the other job templates:
#! characters. This tells the scheduler which
shell should be used to interpret the script. Generally, it is either:
#!/bin/bash for the Bash
(Bourne again shell)#!/bin/tcsh for the Tcsh shell#SBATCH lines. These are comments to the shell, but
pass information to the scheduler about the job. They are discussed
elsewhere in more detail, but briefly:
#SBATCH -n X: indicates that we want the scheduler to reserve
X CPU cores for our job. For a sequential job, we set X to 1.
NOTE: This parameter only determines what resources the scheduler allocates to your job, your
code still needs to be written in such a way that it can use those resources.#SBATCH -t X: indicates how long we want the resources. X
can be an integer number of minutes or something like days-hours:minutes:seconds.
This is the maximum amount of time that your job will run --- the job will be killed if it exceeds
this time limit. If the job completes before this time, you are only charged for the time used,
but making this number too high will increase the amount of time spent waiting in the queue. Pick
a reasonable number, slightly more than you expect the job to actually need.#SBATCH --mem-per-core=X: this sets the amount of memory to be
allocated to the job. X is an integer representing memory in MB. This form of
requesting memory will allocate X MB for every CPU core on the node allocated to the
job (for every node allocated to the job). For a sequential job, there is just the one core,
so this is the total memory allocated. But this form is useful for large parallel jobs.
#SBATCH --exclusive or #SBATCH --share. This determines whether
or not other jobs can reside on the same node while your job is running. --share
means they can, --exclusive means they cannot. If your job runs in exclusive
mode, your job is charged for all cores on the node, as no one else is able to use
them. Although the system tries to prevent jobs running on the same node from interfering with
each other, and doing so is generally safe, we cannot prevent all interference. Typically, we
recommend using --share for jobs significantly smaller than the number of cores
available on the system (e.g. jobs using less than 16 cores on a 20 core node) and --exclusive
for multinode jobs and jobs using most of the cores on a node.
#SBATCH --partition=debug: Many of the job templates contain this line which
directs the job to run on the debug partition.
This is useful for these simple demo cases, as they run quickly it usually allows them to spend less
time in the queue. You will most likely need to remove this in any production jobs, as the debug
partition is limited to 15 minutes of wall time for the jobs.
module command is available.
This is generally needed if the shell interpretting the script (from the shebang line above)
is different from your default login shell, e.g. for a bash script if your default login shell is tcsh.
First we undefine the tap command (failure to do so could cause an error if the script was already processed)
and then process either the .bash_profile or .profile script in your home directory,
which sets up your shell environment properly.
module load commands to add the appropriate software
packages (and specific versions of such if needed) into our environment. We begin by issuing
a module purge and load the standard cluster modulefiles (e.g. hpcc/deepthought2)
so that we have a known list of modules loaded. For this default template,
we only need to module load hello-umd/1.0, but other templates might need to load compilers,
MPI, or other packages. Although one could omit the module purge and rely on modules
loaded in your dot files, it is recommended that one loads all the needed modules in your script.
This will help ensure that your script will still work even if you later change your dot files.
I also recommend including versions in your module loads (e.g. module load hello-umd/1.0
instead of just module load hello-umd --- this records what version of the package
was used to run the job, which can aid in reproducibility.hello-umd
does not produce much output, so we can safely copy it back to the submission directory in your
homespace.
${SLURM_JOBID}) as part of the name. Based on the discussion above,
for sequential jobs we normally place it on the local scratch filesystem (/tmp), and
for MPI jobs we typically use the parallel file system.
slurm-NNNNNNNN.out, where NNNNNNN is the job number
for the job. (You can specify a different filename for this output with the
appropriate SBATCH options).
This information can prove helpful when debugging issues which might arise with more complicated
jobs.
OMPI_MCA_mpi_cuda_support to zero. This
will suppress a warning message about the lack of
CUDA
support on the non-GPU
nodes. As CUDA is overwhelmingly only used for accessing GPUs, we do not
install it on non-GPU nodes. However our OpenMPI codes are GPU aware and will
attempt to load CUDA libraries even on the non-GPU nodes, which causes a
(harmless but annoying) warning message without this setting.which command to extract the full path to the
relevant MPI-enabled code into a variable, which we then use when invoking
the mpirun or similar command.slurm-NNNNNN as above)) ---
this is reasonable if the command is not going to generate a significant amount of output to the standard
output. That is the case for the hello-umd code, and might be the case for codes where the bulk of
the output generated goes into files instead of to standard output (stdout). If your code is going to produce
a significant amount of output to stdout (e.g. over 1000 lines or so),
you should redirect the output to a file in your job script as
putting large amounts of data into the slurm-NNNNNN or equivalent files
can be problematic. Although the hello-umd does not produce a
significant amount of output, we redirect the output to the file hello.out anyway
just to show you how one would do that (the > hello.out 2>&1 instructs
the shell to redirect stdout and stderr from the command to the left of the > to the file
hello.out). When redirecting output to a file, you also should consider on where that
file is located. Generally, that file should be in a directory specific to that job (so that if
multiple copies of the job run at the same time they do not interfere with each other) and should
be on either a high performance parallel file system of the local scratch disk for best performance.
For sequential jobs or single-node jobs, the local scratch disk is generally recommended; for parallel
jobs spanning multiple nodes, the high performance parallel filesystem (e.g. lustre) is usually recommended.
ECODE=$?) saves the exit code from the main command in a variable. This exit code will
typically be 0 if the command completed without serious error (which hopefully means it produced
the expected results), and non-zero if a serious error occurred. Not all codes set the exit code
appropriately, but assuming our code does we save it and then use it to set the exit code for
our job script, which Slurm will then use when it tries to determine whether the job completed
successfully or failed. /tmp), you need to copy any valuable output
to a permanent location before the job ends, as /tmp gets deleted when the job ends.
Here you need to use some common sense; generally it is not advisable to copy GBs of data back to
your home directory (such probably is better placed in the parallel file system).
Since the hello-umd does not output that much, for our default job template we
next copy the hello.uot file back to the submission directory for the OnDemand job
in your homespace. This way it is visible when examining the OnDemand job directory from the web.
work-dir. This way it looks like the working directory for the job is
in the work-dir subdirectory of the OnDemand job directory, making it easier to examine
things from the web interface. NOTE: the data actually resides on the parallel
file system, and does not get deleted when you delect the OnDemand job directory ---
please remember to delete the wokring directory on the parallel file system when you no longer need it.
ECODE)
and exiting with the cached exit code. This will set the exit code for the whole job script to
that of the main command we run. As Slurm uses the exit code of the job script in its determination
of the status of the job, this means Slurm will think the job succeeded if the main command returned
success, and failed if the main command reported failure, which is typically what is wanted. If we
omitted this, the exit code for the job script would default to that of the last command (in this
case the echo command, which always should succeed) and would likely always report success.
Normally, you would make various changes to the submit script or other files in the job directory. If you started with a standard job template, you would likely want to change things so the job performs the calculation you are interested in. If you started with a previously submitted job of yours that failed, you would edit the submit script, etc. in an attempt to fix the problem. If you started with a job than ran successfully, you would edit things to perform a new (probably similar) calculation.
For now, however, we will just run the job as is. As previously mentioned, once you have a
job (and it is selected), a number of buttons above the job listing table become active.
The button Edit Files(F in the screenshot) launches the
OnDemand File Manager starting in the Job directory for the job, and the Open Terminal
button launches shell session to a login node and changes to the job directory,
just like the Open Dir and Open Terminal buttons beneath the submit script
in the Job Detail section (M in screenshot). The Job Options button (G
in the screenshot) will
allow you to change a few options for the job (job name, allocation account charged, and for advanced
users job array options).
But the button we are first concerned with is the Submit button (marked as I
in the screenshot). If you click this button, the Job Composer will submit the job to the scheduler.
At this point, the job becomes both a Job Composer job and a scheduler (Slurm) job. The Status for
the job should change to Queued, indicating that the job was successfully submitted to
the scheduler and is waiting for the scheduler to assign it resources. Jobs from the default Job template
get submitted to the debug partition, and so should start up
quickly (usually less than 15 minutes, often within a minute or two). When the job starts, the Status
will change to Running, and then to Completed when the job finishes. (Because the
debug partition tends to have fast turn around, and the job is very quick to run, you might or might not see
all of the intermediate states, depending on the timing of the job and the refresh of the OnDemand screen.
But you should see the final Completed state.)
Once the job has completed, you should find that two additional files are present in the job directory,
namely the files myscript.out and a file named something like slurm-XXXX.out where
the X-es should be replaced with the job ID. (From earlier parts of this section, you can
see the files using the Edit Files button (F in screenshot) or Open Dir
button at the bottom of the Job Details section (M), or from the Folder contents
list in the Job Details section (M)). The hello.out file contains
the results of running the hello-umd command, because the output of that command was redirected to
that file in the submit script. The slurm*.out file contains all the output from the submit script;
basically the identifying information and time stamps. Although this job should not have produced errors,
if errors occurred they could end up in either file.
Now that you have a job in the job listing section (L in the screenshot), you can select
a job (with one job it is likely already selected) and click on the New Job button (E)
and this time select From Selected Job. This will create a new job directory for the new Job
Composer job, and copy the contents of the selected job's job directory into it. Note that the new job directory
includes the hello.out and slurm*.out files from the previous job --- the Job Composer
is not smart enough to omit those from its cloning process. I would suggest opening the OnDemand
File Manager (e.g. use the Edit Files (F) or Open Dir (at bottom of M)
buttons) and delete those two files --- they still exist in the original job directory, but you generally don't
need or want copies of them. You can edit the job submit script for the new job if desired, or the myscript.sh
if desired, and submit the new job.
Finishing off are discussion of the various components on the Job Composer screen are three more buttons:
Stop button (marked J in the screenshot) is sort of the opposite of the Submit
button. If the selected job is in the queue or running, you can select this button and the job will stop running and be
removed from the queue. The Status field will become Failed. If the job was actually running,
the slurm*.out file should indicate that the job was cancelled. The Job Composer job, its directory, and all
the contents, are still on disk, and you can even resubmit the job if desired (it will get a new Slurm Job ID in that case).
Delete button is more serious. It deletes the currently selected Job Composer job. I.e., the
directory for the job and
all of its contents will be deleted. This is useful to do once you know you will not need the job any more. Because it
is a serious and non-reversible action, you will get a confirmation prompt before deletion occurs.
Create Template button (marked N in the
screenshot). This is for users who are working with DIT to create job templates
for other users in their field.
Contact systems staff if you are interested in developing job templates.
Again, in many cases, production use of an HPC cluster involves the repeated submission of many similar jobs. A typical process for doing this using the Job Composer would likely take place with a sequence like:
While a similar process was always available via the Unix command line, the Job Composer makes this process more accessible to users who are less comfortable with the Unix shell.
Job templates are a way to allow for somewhat easy re-use of existing jobs in creating new jobs.
The previous section discussed how to use the Job Composer to submit jobs based on job templates and/or previously submitted jobs. It included a discussion on recommended practices in job submission scripts, the use of high performance parallel filesystems and/or local scratch storage for jobs, etc.
In this section, we provide descriptions of the various job templates we provide. Note: We are still working on increasing the number of job templates, so you might wish to revisit this page frequently. Also, if you have a job template you think might be useful to the UMD HPC community at large, or wish to work on developing a job template for a specific application with us, feel free to contact systems staff. The currently supported Job Templates are:
hello-umd (same
as < a href="/hpcc/help/examples/submission-sequential.html">HelloUMD Example (sequential)).
hello-umd (same as HelloUMD MPI (gcc,openmpi))
hello-umd (same as HelloUMD MPI (intel,intelmpi))
hello-umd (same as HelloUMD MPI (gcc,openmpi))
mpi4py package and just prints out a hello message from each MPI task. The python script is included
in the template directory.
hello-umd to print a friendly "Hello" message.
hello-umd to print a friendly "Hello" message from each MPI task.
This version is currently the same as HelloUMD MPI (gcc,openmpi)
hello-umd to print a friendly "Hello" message from each MPI task.
This version uses the hello-umd compiled with the GCC compiler and the OpenMPI MPI library.
hello-umd to print a friendly "Hello" message from each MPI task.
This version uses the hello-umd compiled with the Intel compiler and the OpenMPI MPI library.
hello-umd to print a friendly "Hello" message from each MPI task.
This version uses the hello-umd compiled with the Intel compiler and the IntelMPI MPI library.
Many of the examples above use the hello-umd code. This is a very simple
Hello, World! type code,
with sequential and MPI variants. We have compiled it with several compiler/MPI library options
and added it to our HPC software library and
module command so that its usage in the
above examples closely follows that of other software packages. For those interested in
the source code, it is available under /software/hello-umd/src/git.
From the main OnDemand dashboard, on the main upper menu bar select
the My Interactive Sessions. This
will open a browser tab which shows all of your active interactive sessions;
i.e. the interactive sessions belonging to you that are currently running and charging
against your allocation. For each active interactive session, you will see
a section for monitoring/controlling the application, as was described in
the section on Interactive applications.
In particular, you can click on the blue Launch or Connect button to
connect to a disconnected session, or use the red Delete button
to terminate the session.
Note: Interactive jobs are processed through the scheduler, so active interactive sessions will also show up as jobs as discussed in the section below on monitoring batch jobs.
From the main OnDemand dashboard, on the main upper menu bar select
the Jobs drop down, and select Active Jobs. This
will open a browser tab which shows running, pending, and recently completed
jobs.
The jobs are shown in the main section of the page (labeled A
in the diagram below). By default, only your jobs are shown; however there
are two blue drop down menus in the upper right (labeled B in the figure).
The leftmost one of the two allows you to toggle between
viewing just your jobs and seeing all jobs on the cluster. The rightmost one
allows you to toggle between seeing jobs on all clusters or a specific cluster
--- since each portal is currently limited to a single cluster, this button is
not particular useful at this time.
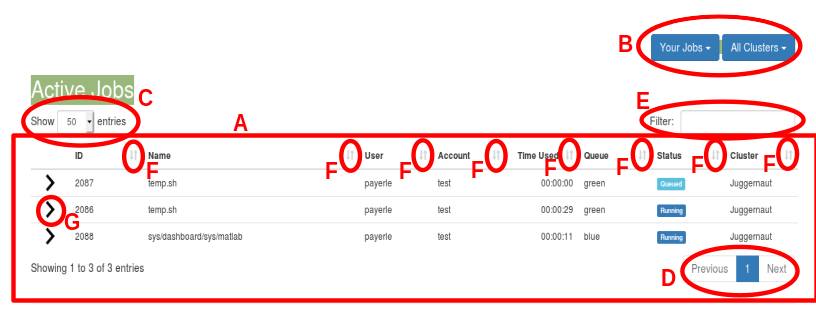
The list of jobs will be limited by default to 50 jobs per page. You can change
this with the control labeled C. Should the list require multiple
pages, you can navigate pages using the widget in the lower right (marked D
in the figure). If the list is long, you can enter terms in the filter box (E
in the diagram) to restrict which jobs are shown. To the right of the field names in
the headings line are up and down arrows (labeled F in the diagram); you
can use these to sort the job list by that field; clicking once will sort on that field
in ascending order, clicking again will switch to descending order for that field.
Only jobs that are queued, running, or recently completed will be shown; once a job finishes it will only continue to be shown in the list for about 5 or 10 minutes or so. The various fields are:
All Jobs
(see button B), it should always be your username.To the left of the job ID colum is a greater than (>) symbol (G in the diagram
above). This is a toggle (when selected it becomes a down arrow) that enables you to dig down
to get more information about a job, as shown in the screenshot below. I believe that if only
a single job is in the list, it defaults to showing the details on the job, otherwise you get
the summary list above.
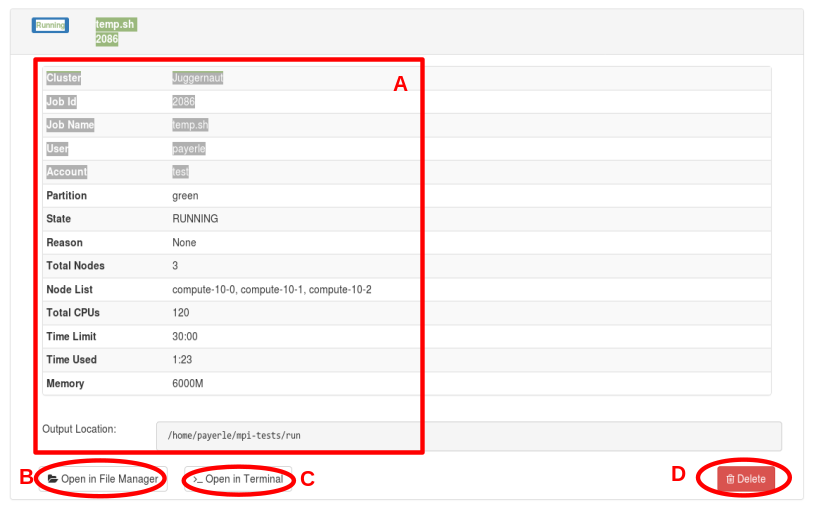
The main section, marked A above, shows more detail about the job. In addition
to the fields described above, it includes the fields:
The Open in File Manager button (marked B in the screenshot) will invoke the
OnDemand file manager on the Output location directory. The Open in Terminal
button (C in screenshot) will use the built in ssh client to ssh to the first compute node for the job and cd to the
Output location directory; you will likely need to provide credentials. The Delete button
(marked D) will cancel/terminate the job.
The OnDemand web portal can also provide shell access to the cluster login nodes. This is a convenient option to use if you do not have a native ssh client on your workstation, and in particular if you need to access the cluster from a public workstation.
|
|
If you ever use OnDemand from a public/shared system, ALWAYS BE SURE
to COMPLETELY EXIT THE BROWSER when you are finished. Otherwise your login
credentials could be stored in session cookies and the next person to use
the machine might be able to access your accounts on the HPC clusters.
|
From the main OnDemand dashboard, select the Clusters
drop-down on the main top menu bar, and select the cluster you wish to access.
This will open a shell terminal session in another browser tab. When finished,
you can just logout and close the browser tab.